From Jupyter Notebooks to Production-Level Code
A Boilerplate Package to Transform Machine Learning Research Notebooks into Deployable Pipelines
 A glimpse to my current notebook. Photo by the author.
A glimpse to my current notebook. Photo by the author.
I love writing and drawing on my notebook. In there, you’ll find not only formulas or flow charts, but also funny cartoons, interminable lists of things I’d like to do, shopping lists, or important scribbles my kids leave me every now and then. Therefore, one could say they are a unique window to what’s going on in my mind and life.
I think something similar happens with the Jupyter notebooks commonly used in data science: they are great because it’s very easy to try new ideas with code in them, you jot down notes beside the features you engineered or the models you tried, and everything is visually great – but the produced content often grows chaotically and it ends up being unusable in real life without proper modifications.
 Photo by
Photo by I have also noticed that I start becoming more sloppy and lazy when I’m too long around notebooks; it’s like when you tend to leave your vegetables unfinished and indulge yourself with cookies for dessert. And then, you try to fit in that wedding suit and you realize it somehow shrunk.
Jupyter Notebooks are like chocolate cookies: You know you should eat them in moderation, but you can’t help sneaking the last one again.
Applying Software Engineering and DevOps to Research Code
Food metaphores aside, and using the jargon of the Software Engineering world, Jupyter notebooks belong to research and development environments, whereas deployed code belongs to production environments. Most of the data science projects don’t leave the research environment, because their goal is to provide useful insights. However, when the created models need to be used in online predictions with new data, we need to level up the code and the infrastructure quality to meet the production standards, characterized by a guarantee of reliability.
Machine learning systems have particular properties that present new challenges in production, as Sculley et al. pointed out in their motivational foundations of what is becoming the field of MLOps. Many tools which target those specific needs have appeared in recent years; those tools and the applications which use them are often categorized in maturity levels:
- Level 0 (research and development): data analysis and modeling is performed to answer business questions, but the models are not used to perform online inferences.
- Level 1 (production): the inference pipeline is deployed manually and the artifact versions are tracked (models, data, code, etc.) and pipeline outputs monitored.
- Level 2 (very serious production): deployments of training and inference pipelines are done automatically and frequently, enabling large-scale continuously updated applications.
Small/medium-sized projects (teams of 1-20 people) require typically level 1 maturity, and often, the companies where they are implemented in don’t have the resources to go for level 2.
In this article, I present a standardized way of transforming research notebooks into production-level code; in MLOps maturity levels that represents the journey from level 0 to 1. To that end, I have implemented a boilerplate project with production-ready quality that can be cloned from this Github repository.
The selected business case consists in analyzing customer churn using the Credit Card Customers dataset from Kaggle. Data analysis, modeling and inference pipelines are implemented in the project to end up with an interpretable model-pipeline that is also able to perform reliable predictions. However, the package is designed so that the business case and the data analysis can be easily replaced, and the focus lies in providing a template with the following properties:
- Structure which reflects the typical steps in a small/medium-sized data science project
- Readable, simple, concise code
- PEP8 conventions applied, checked with pylint and autopep8
- Modular and efficient code, with Object-Oriented patterns
- Documentation provided at different stages: code,
READMEfiles, etc. - Error/exception handling
- Execution and data testing with pytest
- Logging implemented during production execution and testing
- Dependencies controlled for custom environments
- Installable python package
- Basic containerization with Docker
However, two properties are missing to reach full level 1:
- Deployment of the pipeline
- Tracking of the generated artifacts (model-pipelines, data, etc.)
- Monitoring of the model (drift)
Those are fundamental attributes, but I consider they are out of scope in this article/project, because they often rely on additional 3rd party tools. My goal is to provide a template to transform notebook code into professional software using the minimum additional tools it is possible; after that, we have a solid base to add more layers that take care of the tracking and monitoring of the different elements.
The Boilerplate
The boilerplate project from the Github repository has the following basic file structure:
.
├── README.md # Package description, usage, etc.
├── churn_notebook.ipynb # Research notebook
├── config.yaml # Configuration file for production
├── customer_churn/ # Production library, package
│ ├── __init__.py # Python package file
│ ├── churn_library.py # Production library
│ └── transformations.py # Utilities for the library
├── data/ # Dataset folder
│ ├── README.md # Dataset details
│ └── bank_data.csv # Dataset file
├── main.py # Executable of production code
├── requirements.txt # Dependencies
├── setup.py # Python package file
└── tests/ # Pytest testing scripts
├── __init__.py # Python package file
├── conftest.py # Pytest fixtures
└── test_churn_library.py # Tests for churn_library.py
All the research work of the project is contained in the notebook churn_notebook.ipynb; in particular, simplified implementations of the typical data processing and modeling tasks are performed:
- Data Acquisition/Import
- Exploratory Data Analysis (EDA)
- Data Processing: Data Cleaning, Feature Engineering (FE)
- Data Modelling: Training, Evaluation, Interpretation
- Model Scoring: Inference
The code from churn_notebook.ipynb has been transformed to create the package customer_churn, which contains two files:
churn_library.py: this file contains most of the refactored and modified code from the notebook.transformations.py: definition of auxiliary transformations used in the data processing; complex operations on the data are implemented in Object-Oriented style so that they can be cleanly applied as with thesklearn.preprocessingpackage.
Additionally, a tests folder is provided, which contains test_churn_library.py. This script performs unit tests on the different functions of churn_library.py using pytest.
The executable or main function is provided in main.py; this script imports the package customer_churn and runs three functions from churn_library.py:
run_setup(): the configuration fileconfig.yamlis loaded and auxiliary folders are created, if not there yet:images: it will contain the images of the EDA and the model evaluation.models: it will contain the inference models/pipelines as serialized objects (pickles).artifacts: it will contain the data processing parameters created during the training and required for the inference, serialized as pickles.
run_training(): it performs the EDA, the data checks, the data processing and modeling, and it generates the inference artifacts (the model/pipeline), which are persisted as serialized objects (pickles). In the provided example, logistic regression, support vector machines and random forests are optimized in a grid search to find the best set of hyperparameters.run_inference(): it shows how the inference artifacts need to be used to perform a prediction; an exemplary dataset sample created during the training is used.
The following diagram shows the workflow:
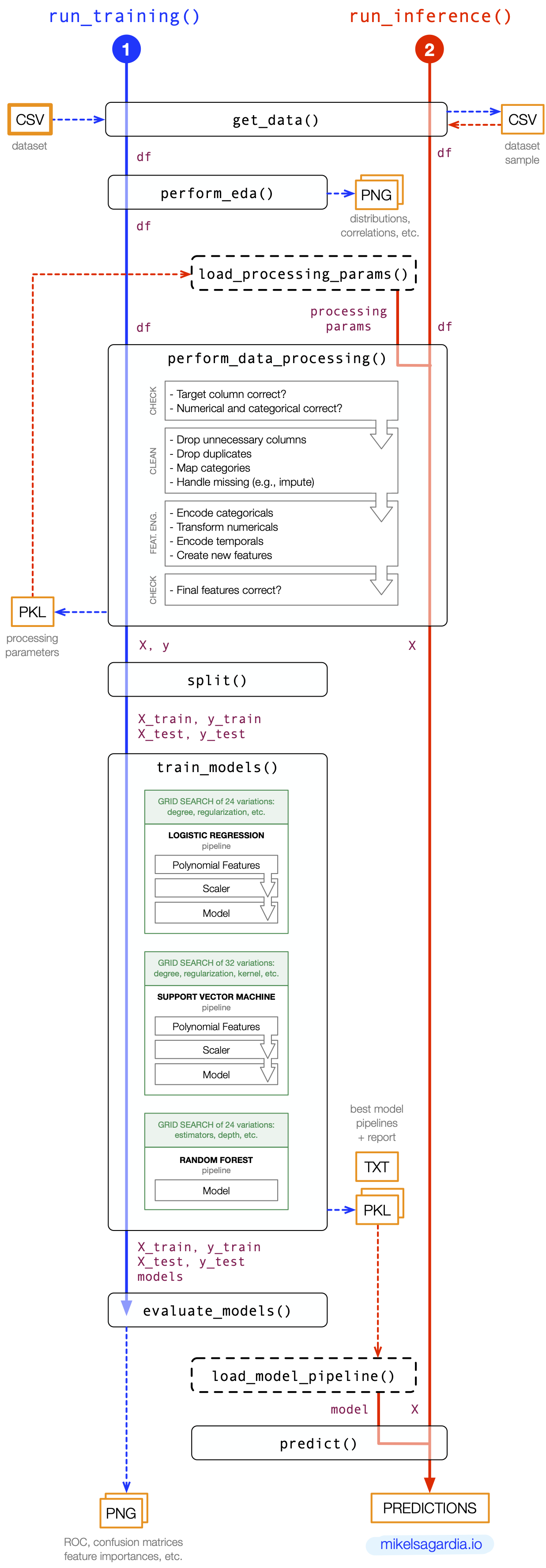
Although the training and the inference pipeline represented by run_training() and run_inference() should run sequentially one after the other, the symmetry of both is clear; in fact, a central property of the package is that run_training() and run_inference() share the function perform_data_processing(). When perform_data_processing() is executed in run_training(), it generates the processing parameters and stores them to disk. In contrast, when perform_data_processing() is executed in run_inference(), it loads those stored parameters to perform the data processing for the inference.
Note that the implemented run_inference() is exemplary and it needs to be adapted:
- Currently, it is triggered manually and it scores a sample dataset from a
CSVfile offline; instead, we should wait for external requests that feed new data to be scored. - The data processing parameters and the model should be loaded once in the beginning (hence, the dashed box) and used every time new data is scored.
Those intentional loose ends are to be tied when deciding how to deploy the model, which is not in the scope of this repository, as mentioned.
Finally, note that this boilerplate is designed for small/medium datasets, which are not that uncommon in small/medium enterprises; in my experience, its structure is easy to understand, implement and adapt. However, as the complexity increases (e.g., when we need to apply extensive feature engineering), it is recommended to apply these changes to the architecture:
- All data processing steps should be written in an Object Oriented style and packed into a Scikit-Learn
Pipeline(or similar), as done intransformations.py. - Any data processing that must be applied to new data should be integrated in the inference pipeline generated in
train_models(); that means that we should integrate most of the content inperform_data_processing()as aPipelineintrain_models(). Thus,perform_data_processing()would be reduced to basic tasks related to cleaning (e.g., duplicate removal) and checking.
More details on the package can be found on the source Github repository.
Conclusions
In this article I introduced my personal boilerplate to transform small/medium-sized data science projects into production-ready packages without exposing to many 3rd party tools. The template works on the customer churn prediction problem using the Credit Card Customers dataset from Kaggle, but you are free to clone the boilerplate from its Github repository and modify it for your business case. Important software engineering aspects as covered, such as, clean code conventions, modularity, reproducibility, logging, error and exception handling, testing, dependency handling with environments – and more.
Topics such as data processing techniques, pipeline deployment, artifact tracking and model monitoring are out of scope; for them, have a look at the following links:
- A 80/20 Guide for Exploratory Data Analysis, Data Cleaning and Feature Engineering.
- A Boilerplate for Reproducible and Tracked Machine Learning Pipelines with MLflow and Weights & Biases and Its Application to Song Genre Classification.
- Deployment of a Census Salary Classification Model Using FastAPI.
- If you are interested in more MLOps-related content, you can visit my notes on the Udacity Machine Learning DevOps Engineering Nanodegree: mlops_udacity.
Do you find the boilerplate helpful? What would you add or modify? Do you know similar templates to learn from?