Applying Parameter-Efficient Fine-Tuning (PEFT) to a Large Language Model (LLM)
A Conceptual Guide for Developers & ML Practitioners
 Two stochastic parrots dressed up like Star Wars and Star Trek characters; same parrot, different costumes and roles. Image generated using Dall-E 3; prompt: Wide landscape cartoon illustration of two red-blue-yellow macaws with sunglasses on tree branches in a bright green forest. Left parrot dressed as a Jedi with robe and blue lightsaber, right parrot dressed as a classic Star Trek Vulcan officer in a gold uniform. Bold, vibrant vector style.
Two stochastic parrots dressed up like Star Wars and Star Trek characters; same parrot, different costumes and roles. Image generated using Dall-E 3; prompt: Wide landscape cartoon illustration of two red-blue-yellow macaws with sunglasses on tree branches in a bright green forest. Left parrot dressed as a Jedi with robe and blue lightsaber, right parrot dressed as a classic Star Trek Vulcan officer in a gold uniform. Bold, vibrant vector style.
In my previous post I explained how LLMs are built, and how they work. In this post, I will try to explain how to adapt LLMs easily to specific tasks and domains using HuggingFace’s peft library. As explained on the official site, PEFT (Parameter-Efficient Fine-Tuning) is a family of techniques that
“only fine-tune a small number of (extra) model parameters — significantly decreasing computational and storage costs — while yielding performance comparable to a fully fine-tuned model. This makes it more accessible to train and store large language models (LLMs) on consumer hardware.”
In summary, I cover the following topics in this post:
- What task and domain adaptation of LLMs is, and which techniques are commonly used for it.
- How PEFT/LoRA works, and how it reduces the number of trainable parameters by orders of magnitude.
- Explanation of a Jupyter Notebook that implements PEFT/LoRA on a DistilBERT model for a text classification task, using the AG News dataset.
Let’s start!
Why and How Should We Adapt LLMs?
First of all, we should define some terminology:
- A Task: a specific problem we want to solve. The task is usually defined by the input and the output formats. Typically, LLMs are trained on the general task of language modeling: predicting the next word/token given an input sequence (i.e., the context); as such, they are able to generate coherent text related to the input. However, we can change their output layers (also known as heads) to perform other tasks, such as text classification (e.g., sentiment analysis and topic classification), token classification (e.g., named entity recognition or NER), etc.
- A Domain: the specific area or context to which the training texts belong and in which the task needs to be performed. Typically, LLMs are trained on a wide variety of texts from the Internet, which makes them generalists. However, we may want to adapt them to specific domains, such as medicine, finance, legal, etc. The more niche the domain, the more we may need to adapt the LLM to it to learn style, jargon, and specific knowledge.
This task and domain adaptation, although referred to as fine-tuning in the LLM world, is known as transfer learning in the context of computer vision. Howard and Ruder (2017) showed that a language model trained on a large corpus can be adapted for smaller corpora and other downstream tasks.
One common approach in the PEFT library is the Low-Rank Adaptation (or LoRA, introduced by Hu et al., 2021), which I cover in more detail in the next section. In a nutshell: LoRA freezes the pre-trained weight matrices $W$ and adds to them new matrices $dW$, which are the ones that are trained. These $dW$ matrices are factored as the multiplication of two low-rank matrices; that trick reduces trainable parameters by orders of magnitude and maintains or matches full fine-tuning performance on many benchmarks.
There are other ways to adapt LLMs which I won’t cover here, such as:
- RLHF (Reinforcement Learning with Human Feedback): This technique was used to align the initial ChatGPT model (GPT 3.5) with human preferences. Initially, human annotators ranked outputs of a GPT model. Then, these annotations were used to train a reward model (RM) to automatically predict the output score. And finally, the GPT model (policy) was trained using the Proximal Policy Optimization (PPO) algorithm, based on the conversation history (state) and the outputs it produced (actions), and using the reward model (reward) as the evaluator.
- RAG (Retrieval Augmented Generation): This method consists in outsourcing the domain-specific memory of LLMs. In an offline ingestion phase, the knowledge is chunked and indexed, often as embedding vectors. In the real-time generation phase, the user asks a question, which is encoded and used to retrieve the most similar indexed chunks; then, the LLM is prompted to answer the question by using the found similar chunks, i.e., the retrieved data is injected in the query. RAGs reduce hallucinations and have been extensively implemented recently.
In my experience, usually PEFT/LoRA and RAG are the most used techniques and they can be used in combination:
- PEFT/LoRA makes sense when we need to approach a task different than language modeling (i.e., next token prediction), or when we have a very specific domain, such as medicine or finance, which is not well represented in the general training data of the LLM.
- RAG is more useful when we have a task that can be solved by retrieving specific information, such as question answering or summarization, and when we have a large amount of domain-specific data that changes constantly. Most chatbots that are used in production for customer support, for instance, are RAG-based.
How Does PEFT/LoRA Work?
When we apply Low-Rank Adaptation (LoRA), we basically decompose a weight matrix into a multiplication of low-rank matrices that have fewer parameters.
Let’s consider a pre-trained weight matrix $W$; instead of changing it directly, we add to it a weight offset $dW$ as follows:
\[\hat{W} = W + dW,\]where
- $\hat{W}$ represents the adapted weight matrix $(d, f)$
- and $dW$ is a weight offset to be learned, of shape $(d, f)$.
However, we do not operate directly with the weight offset $dW$; instead, we factor it as the multiplication of two low-rank matrices:
\[dW = A \cdot B,\]where
- $A$ is of shape $(d, r)$,
- $B$ is of shape $(r, f)$,
- and $r « d, f$.
The key idea is that during training we freeze $W$ while we learn $dW$; however, instead of learning the full-sized $dW$, we learn the much smaller matrices $A$ and $B$. The forward pass of the model is modified as follows:
\[y = x \cdot W = x \cdot (W + dW) = x \cdot (W + A \cdot B).\]The proportion of weights in $dW$ as compared to $W$ is the following:
- Weights of $W$: $d \cdot f$
- Weights of $A$ and $B$: $r \cdot (d + f)$
- Proportion: $r\cdot\frac{d + f}{d \cdot f}$
Note that the number of trainable parameters is reduced by controlling the rank value $r$; for instance, if we set $r=4$, we can reduce the number of trainable parameters by more than 100x for a weight matrix of size $(4096, 4096)$.
LoRA is not applied to all weight matrices, but usually the library (peft) decides where to apply it; e.g.: projection matrices $Q$ and $V$ in attention blocks, MLP layers, etc. And, after training, we can merge $W + dW$, so there is no latency added!
In practice, LoRA assumes that the task-specific update to a large weight matrix lies in a low-dimensional subspace — and therefore can be efficiently represented with low-rank matrices.
In addition to LoRA, quantization is often applied to further reduce the model size and speed up inference. Quantization consists in reducing the precision of the weights from 32-bit floating point values to 16-bit or even 4-bit representations (as in QLoRA); in other words, high-precision floats are approximated using only k bits. This is achieved by scaling and mapping the original values to a smaller discrete set, sometimes combined with truncating less significant information. Quantization can be easily applied using the library bitsandbytes, which is very well integrated with the HuggingFace ecosystem.
Implementation Notebook
Thanks to the peft library, applying PEFT/LoRA to an LLM is very easy. The Github repository I have prepared contains the Jupyter Notebook llm_peft.ipynb, in which I provide an example.
There, I fine-tune the DistilBERT pre-trained model; DistilBERT is a smaller version of the encoder-only BERT that has been distilled to reduce its size and computational requirements, while maintaining good performance. An alternative could have been RoBERTa, which was trained roughly on 10x more data than BERT and has approximately twice the parameters of DistilBERT. We could use other models, too, e.g., generative decoder transformers like GPT-2, although in general RoBERTa seems to have better performance for classification tasks. GPT-2 is similar in size to RoBERTa.
The dataset I use is ag_news, which consists of roughly 127,600 news texts, each of them with a label related to its associated topic: 'World', 'Sports', 'Business', 'Sci/Tech' (perfectly balanced). Thus, the task head is text classification (with 4 mutually exclusive categories) and the domain is news.
The notebook is structured in clear sections and comments, which I won’t fully reproduce here; the core steps are the following:
- Dataset splitting: I divide the 127,600 samples into the sets
train(108k samples),test(7.6k), andvalidation(12k). - Tokenization: The
AutoTokenizeris instantiated with thedistilbert-base-uncasedpre-trained subword tokenizer. - Feature exploration: some exploratory data analysis is performed.
- Model setup: the
AutoModelForSequenceClassificationis instantiated with thedistilbert-base-uncasedpre-trained model, and thePeftModelis instantiated with the LoRA configuration. - Training: the
Trainerclass is instantiated with the model, theTrainingArguments, and the datasets; then, thetrain()method is called to start training. - Evaluation: we use the
evaluate()method of theTrainerto evaluate the model on the test set, and we compute our custom metrics (accuracy, precision, recall, and F1), as defined incompute_metrics().
The feature exploration reveals that learning the classification task is going to be quite easy for the model. The function extract_hidden_states() is used to extract the last hidden states computed by the model, after each sample is passed through it. Then, these sample embeddings are mapped to 2D using UMAP, and plotted in a hexagonal plot colored by class. As we can see, each class occupies a different region in the embedding space without any fine-tuning — that is, the model already has a good understanding of the differences between the classes.
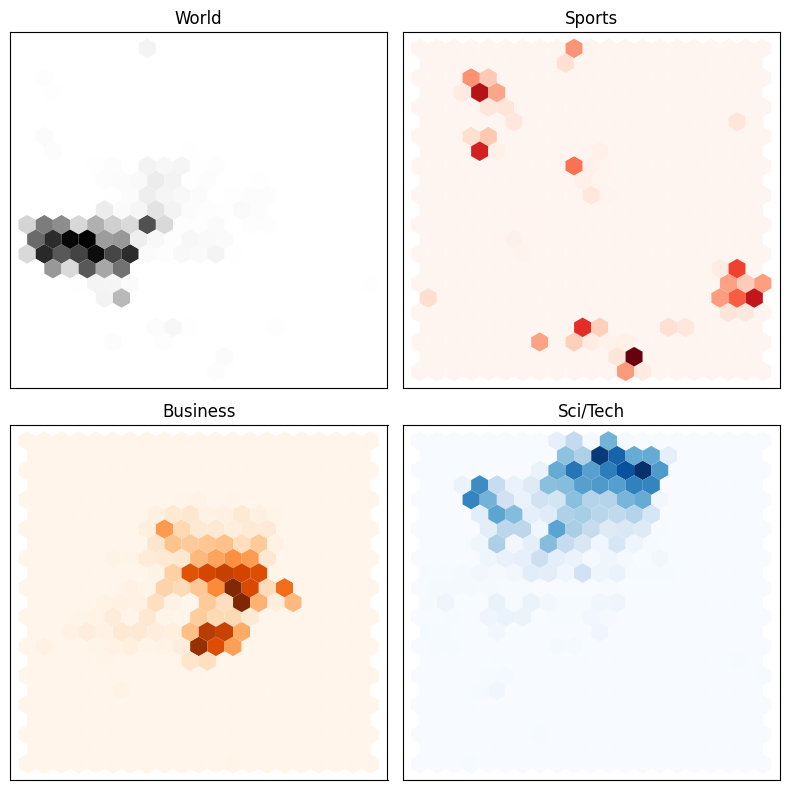 A hexagonal plot of the embeddings from the AG News dataset according to their classes. The embeddings are the last hidden states of the DistilBERT model, and they were reduced to 2D using UMAP. Image by the author.
A hexagonal plot of the embeddings from the AG News dataset according to their classes. The embeddings are the last hidden states of the DistilBERT model, and they were reduced to 2D using UMAP. Image by the author.
The key aspect is the model setup for training, which is very straightforward thanks to the HuggingFace ecosystem. The code snippet below shows all the steps:
# Quantization config (4-bit for minimal memory usage)
# WARNING: This requires the `bitsandbytes` library to be installed
# and Intel CPU and/or 'cuda', 'mps', 'hpu', 'xpu', 'npu'
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Activate 4-bit quantization
bnb_4bit_use_double_quant=True, # Use double quantization for better accuracy
bnb_4bit_compute_dtype="bfloat16", # Use bf16 if supported, else float16
bnb_4bit_quant_type="nf4", # Quantization type: 'nf4' is best for LLMs
)
# Transformer model: we re-instantiate it to apply LoRA
# We should get a warning about the model weights not being initialized for some layers
# This is because we have appended the classifier head and we haven't trained the model yet
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=len(id2label),
id2label=id2label,
label2id=label2id,
quantization_config=bnb_config,
device_map="auto" # Optional: distributes across GPUs if available
)
# LoRA configuration
# We need to check the target modules for the specific model we are using (see below)
# - For distilbert-base-uncased, we use "q_lin" and "v_lin" for the attention layers
# - For bert-base-uncased, we would use "query" and "value"
# The A*B weights are scaled with lora_alpha/r
lora_config = LoraConfig(
r=16, # Low-rank dimensionality
lora_alpha=32, # Scaling factor
target_modules=["q_lin", "v_lin"], # Submodules to apply LoRA to (model-specific)
lora_dropout=0.1, # Dropout for LoRA layers
bias="none", # Do not train bias
task_type=TaskType.SEQ_CLS # Task type: sequence classification
)
# Get the PEFT model with LoRA
lora_model = get_peft_model(model, lora_config)
# Define training arguments
training_args = TrainingArguments(
learning_rate=2e-3,
weight_decay=0.01,
num_train_epochs=1,
eval_strategy="steps",
save_strategy="steps",
eval_steps=200,
save_steps=200,
# This seems to be a bug for PEFT models: we need to specify 'labels', not 'label'
# as the explicit label column name
# If we are not using PEFT, we can ignore this argument
label_names=["labels"], # explicitly specify label column name
output_dir="./checkpoints",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
load_best_model_at_end=True,
logging_dir="./logs",
report_to="tensorboard", # enable TensorBoard, if desired
)
# Initialize the Trainer
trainer = Trainer(
model=lora_model, # Transformer + Adapter (LoRA)
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
processing_class=tokenizer,
compute_metrics=compute_metrics,
)
After training, the model achieves an F1 score of 0.90 on the test set (compared to 0.16 before fine-tuning), which is a very good result for this task.
Other aspects are covered in the notebook, such as:
- The training can be monitored using TensorBoard.
- A
predict()custom function is provided, which takes an input text, tokenizes it, passes it through the model, and decodes the predicted label. - LoRA weights are merged and the model is persisted. Merging the LoRA weights consists in computing every $dW$ and adding them to the corresponding $W$; as mentioned before, after merging, the model can be used for inference without any latency increase.
- Some error analysis is performed by looking at the misclassified samples.
- Finally, model packaging is addressed using ONNX. This is also straightforward thanks to the HuggingFace & PyTorch ecosystem, yet essential to be able to deploy the model in production.
Summary and Conclusion
In this post, I have explained how to adapt LLMs to specific tasks and domains using Parameter-Efficient Fine-Tuning (PEFT), and more concretely, Low-Rank Adaptation (or LoRA, introduced by Hu et al., 2021). This technique allows us to train only a small number of parameters while maintaining good performance, which makes it accessible to train and store large language models on consumer hardware.
I have used the classification task applied to the AG News dataset, but many more tasks are possible: token classification (e.g., named entity recognition), question answering, summarization, etc.
Which task and domain would you like to adapt an LLM to?
I think that the HuggingFace ecosystem is incredible, as it offers plethora of pre-trained models, datasets, and libraries that make it very easy to work with LLMs, from research to production.
If you would like to deepen your understanding of the topic, consider checking these additional resources:
- LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021)
- Hugging Face LoRA conceptual guide
- HuggingFace Guide:
mxagar/tool_guides/hugging_face - My personal notes on the O’Reilly book Natural Language Processing with Transformers, by Lewis Tunstall, Leandro von Werra and Thomas Wolf (O’Reilly)
- My personal notes and guide for the Generative AI Nanodegree from Udacity